 ©Wikimedia
©Wikimedia
S'il faut en croire la cosmogonie japonaise, le Namazu est le grand poisson-chat sur lequel repose l'archipel, et dont les humeurs sont à l'origine des tremblements de terre qui l'affectent.
Plus prosaïquement, c'est un système d'indexation de fichiers et un moteur de recherche, qui vous permettra de retrouver vos aiguilles dans vos bottes de foin, comparable par ses fonctionnalités à des concurrents mieux connus tels que Xapian/Omega, Swish++,Htdig, etc.
Bien que destiné à l'indexation de mes fichiers personnels, je souhaitais un système consultable via une interface web, parce que - comme la plupart d'entre nous - j'ai toujours un navigateur ouvert, et que sous l'influence de qui-vous-savez, agir ainsi est devenu la manière la plus spontanée d'effectuer des recherches.
J'ai retenu Namazu (http://www.namazu.org/ ) parce que son installation s'est déroulée sans difficulté, que sa documentation est simple et concise, et surtout parce que son interface web s'est avérée suffisamment adaptable pour en obtenir ce que je souhaitais1. Également parce qu'il est codé en Perl, comme d'ailleurs ses fichiers de configuration, ce qui en rend l'adaptation aisée avec quelques rudiments de celui-ci (pour l'utilisation d'expressions régulières par exemple).
Pour entrer dans le sujet sans s'encombrer de détails, la configuration par défaut sur la Debian créera les index dans
/var/lib/namazu/index
On indexe les documents souhaités de cette manière:
# mknmz -O /var/lib/namazu/index /home/user/fichiers_a_indexer
Outre les fichiers d'index proprement dit, cet utilitaire créera dans le répertoire de destination des fichiers qui constitueront les templates des fichiers html renvoyés par le script CGI, dans différentes langues:
NMZ.body.fr NMZ.foot.fr NMZ.head.fr NMZ.result.normal.fr NMZ.result.short.fr NMZ.tips.fr
qu'il sera possible de personnaliser.
Le manuel de Namazu propose une otion supplémentaire de la forme
--replace='s#/foo/bar/doc/#http://localhost/doc/#'
ce qui a pour effet de substituer au chemin menant vers un fichier le chemin qui sera inclus dans l'URL proposée par le script (on reconnaît une regexp où le séparateur est le dièse au lieu du slash conventionnel, ce qui est plus pratique quand les chaînes de caratères comprennent elles-mêmes des "/"). Cette précision est essentielle et variable selon les cas particuliers, car sinon les résultats de recherche pointeront vers un chemin qui selon toute vraissemblance ne sera pas accessible au serveur web.
Mais Namazu a évolué pour proposer un mécanisme de substitution qui est à présent intégré aux fichiers de configuration. C'est beaucoup plus puissant, parce qu'il est possible se spécifier de manière séquentielle plusieurs règles (toujours sous forme d'expressions régulières) qui permettent par exemple de spécifier un chemin différent selon l'extension du fichier. Et cela évite de stocker «en dur» dans l'index des url qu'on serait amené à modifier pour une raison ou l'autre, comme un changement de nom d'hôte.
Cette option ne me paraît donc plus recommandable.
Dès que c'est terminé, et pour autant qu'on ait configuré correctement la substitution dans les chemins d'accès, on peut pointer son navigateur sur http://localhost/cgi-bin/namazu.cgi
À titre d'exemple,j'ai indexé toute la documentation issue des paquets de mon système Debian, dans /usr/share/doc:
# mknmz -O /var/lib/namazu/index/doc/ /usr/share/doc Recherche des fichiers a indexer... 20013 fichiers trouves pour etre indexes. 1/20013 - /usr/share/doc/HOWTO/fr-txt/3-Button-Mouse.txt.gz [text/plain] 2/20013 - /usr/share/doc/HOWTO/fr-txt/3Dfx-HOWTO.txt.gz [text/plain] 3/20013 - /usr/share/doc/HOWTO/fr-txt/ACPI-HOWTO.txt.gz [text/plain] (etc.) 19348/19349 - /usr/share/doc/zlib1g/changelog.Debian.gz [text/plain] 19349/19349 - /usr/share/doc/zlib1g/changelog.gz [text/plain] Ecriture des fichiers d'index... [Base] Date : Fri Apr 30 18:16:02 2010 Documents ajoutes : 19,349 Taille (octets) : 663,340,127 Total Documents : 19,349 Mots clefs ajoutes : 3,444,208 Total mots clefs : 3,444,208 Wakati : module_kakasi -ieuc -oeuc -w Temps (secondes) : 6,552 Fichiers/seconde : 2.95 Systeme : linux Perl : 5.010000 Namazu : 2.0.18
Inutile de préciser que dans le cas de /usr/share/doc/, c'était un gros morceau... 648 Mo de documentation (dont une grosse part est constituée par celle de LaTeX), dont il résultera un index d'une taille de 164 Mo, un besoin d'espace disque qui n'est donc pas négligeable. Ni le temps d'exécution, une dizaine d'heures 2. Mais pour les mises à jours qui suivront (après l'installation de nouveaux paquets sur le système), le programme détectera les fichiers ajoutés ou modifiés, et seuls ceux-ci seront examinés, ce qui sera beaucoup plus rapide.
J'ai alors remarqué que les résultats de recherche incorporaient fréquemment, et sans que ça représente d'intérêt, les fichiers changelog, ceux de copyright, etc. J'ai donc effectué une mise à jour en précisant ainsi que ces fichiers devaient être exclus:
# mknmz -O /var/lib/namazu/index/doc/ \
--deny="((news|changelog)(\.debian)*|copyright)\.gz" /usr/share/docRésultat:
Documents effaces : 3,351
Une fonctionnalité qui m'atirait particulièrement était de répartir les documents indexés en plusieurs index. Selon l'objet de la recherche, il est en effet rarement opportun de fouiller indifféremment dans la documentation du système, les documents personnels, les e-mails, etc. Pour ne pas être confronté à des résultats de recherche en surabondance, Namazu permet ainsi de sélectionner - ou non - des sous-domaines de recherche.
Cette manière de procéder a comme conséquence que pour rafraîchir les index, il faut utiliser une commande dédiée pour chacun de ceux-ci. Ce qu'on peut considérer comme un avantage puisque cela permet d'indiquer des options particulières pour chaque cas3.
J'ai ainsi indexé des documents personnels, et les pages de manuel. Pour ces dernières, il fallait une expression régulière qui exclue toutes celles qui ne soient ni en français, ni en anglais, ce qui a donné la commande suivante:
# mknmz -O /var/lib/namazu/index/man \
--exclude='/usr/share/man/(?!(man[1-8]|fr))' /usr/share/manLa configuration que j'ai retenue est inspirée de celle citée dans le manuel[1] du logiciel, et demande de créer pour chaque sous-ensemble un répertoire:
/var/lib/namazu/index/
doc/
man/
oreilly/
perso/Le répertoire index ne comprend aucune donnée d'index, mais seulement les templates des fichiers html de l'interface, que j'ai adaptés. Les templates des sous-répertoires sont des liens symboliques vers ceux-là.
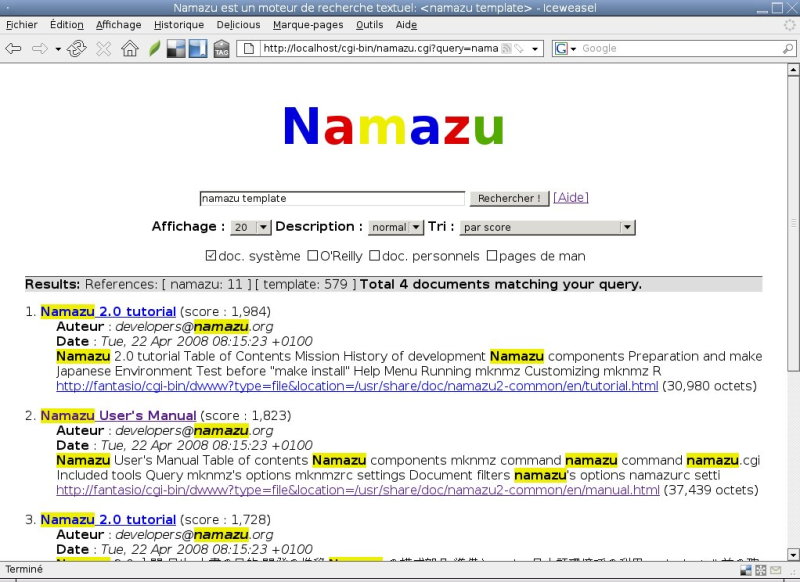
Le formulaire html (template :NMZ.head.fr) comprend:
<p>
<input type="checkbox" name="idxname" value="doc">doc. système</li>
<input type="checkbox" name="idxname" value="oreilly">O'Reilly</li>
<input type="checkbox" name="idxname" value="perso">doc. personnels</li>
<input type="checkbox" name="idxname" value="man">pages de man</li>
</p>ce qui donne une page de cette forme:
À ce stade, il restait un inconvénient, le fait que le serveur renvoie des pages qui ne s'affichent pas directement dans le navigateur, en particulier les fichiers gzippés et les pages de man. Heureusement, le mécanisme de substitution dans les URLs permet de faire appel à un script cgi. Plutôt que de réinventer la roue, j'ai utilisé un script présent dans dwww, un paquet de la Debian destiné précisément à accéder à la documentation système via une interface web: http://packages.debian.org/lenny/dwww 4 et inclus dans /etc/namazu/namazurc les directives suivantes:
Replace (/usr/share/doc/.*$) \ http://fantasio/cgi-bin/dwww?type=file&location=\1 Replace (/usr/share/man/.*$) \ http://fantasio/cgi-bin/dwww?type=man&location=\1
(les sauts de ligne "\" ne figurent pas dans le fichier original)
Autres fonctionnalités
Namazu se sert de filtres pour examiner le contenu de différents types de fichiers:
$ ls /usr/share/namazu/filter apachecache.pl gzip.pl mailnews.pl pdf.pl taro56.pl bzip2.pl hdml.pl man.pl pipermail.pl taro7_10.pl compress.pl hnf.pl mhonarc.pl postscript.pl taro.pl deb.pl html.pl mp3.pl powerpoint.pl tex.pl dvi.pl image.pl msofficexml.pl rfc.pl visio.pl excel.pl koffice.pl msword.pl rpm.pl zip.pl gnumeric.pl macbinary.pl ooo.pl rtf.pl
Les plus courageux peuvent donc étendre ses fonctionnalités  .
.
Namazu fonctionne en ligne de commande selon la syntaxe
$ namazu [options] <requete> [index]
# namazu -l -R "utf-8 recode" /var/lib/namazu/index/doc /usr/share/doc/HOWTO/fr-txt/Unicode-HOWTO.txt.gz /usr/share/doc/debian-reference-common/html/debian-reference.fr.html /usr/share/doc/xterm/xterm.log.html /usr/share/doc/perl-doc-html/html/perluniintro.html /usr/share/doc/debian-reference-common/html/ch-tune.fr.html /usr/share/doc/debian-reference-common/html/debian-reference.fr.txt.gz /usr/share/doc/debian-reference-common/html/ch12.en.html /usr/share/doc/debian-reference-common/html/ch-tips.fr.html /usr/share/doc/wordtrans-doc/wordtrans.txt.gz (...)
Les options utilisées ici fournissent une liste simple (-l) au lieu d'une description étendue et désactivent (-R) le mécanisme de substitution des urls ce qui permet d'obtenir la liste des fichiers. On dispose ainsi d'une sorte de «super-grep» extrêmement rapide.
Namazu indexe les meta-données de la plupart des types de documents: les en-têtes des fichiers html et des emails, les tags des fichiers mp3, les titres et auteurs des fichiers pdf, etc. Il est donc possible d'affiner ses recherches de cette manière:
+from:"Larry Wall" +author:"Randal Schwartz"
Ces deux champs sont équivalents, de même que +title: ou +subject:. Attention d'accoler le premier guillemet au deux-points. Voir la section #query-field du manuel. À titre d'exemple, une recherche sur find dans les pages de manuel renvoie 1047 résultats  tandis qu'en précisant +subject:find, on n'en retrouve que 25, dont celle de find en premier lieu.
tandis qu'en précisant +subject:find, on n'en retrouve que 25, dont celle de find en premier lieu.
Namazu peut utiliser les expressions régulières en plus des expressions boléennes ordinaires dans les requêtes:
/syst[eè]me/
mais ça ralentit considérablement la recherche, et on dépasse assez souvent le nombre limite de résultats.
Pour conclure
Je ne vais pas m'avancer au sujet des qualités respectives des moteurs d'indexation et de la pertinence de leurs résultats. Je ne sais pas où se situe Namazu sur ce plan, mais je constate que les réponses aux requêtes sont extrêmement rapides, et qu'il me rend bien service. Etl'indexation proprement dite peut être confiée à (ana)cron; je suis occupé à juger de l'effet du fichier /etc/cron.weekly/mknmz suivant:
#!/bin/sh # $Id: imknmz.cron.weekly,v 0.1 2010-05-17 gv $ # # check if mknmz is installed test -x /usr/bin/mknmz || exit 0 mknmz -O /var/lib/namazu/index/man --exclude='/usr/share/man/(?!(man[1-8]|fr))' /usr/share/man mknmz -O /var/lib/namazu/index/perso /home/gv/docs mknmz -O /var/lib/namazu/index/doc /usr/share/doc
Peut-être faire intervenir nice ?
Vu que Namazu peut indexer les emails pour autant qu'ils soient scindés en fichiers isolés, je réfléchis à convertir mes archives du format mbox[2] au maildir[3]. Il existe un logiciel utilisant namazu avec mutt: http://www.ecademix.com/JohannesHofmann/nmzmail.html mais son principe me semble un peu étrange, il crée pour chaque requête un répertoire comprenant des fichiers symboliques vers les messages correspondant au résultat. À tester, donc... D'un autre côté, si je trouvais un simple script CGI pour afficher joliment un mail et ses pièces jointes dans un navigateur, ça me suffirait amplement.